


这篇文章网上给的解读很多,我大概就从贡献和方法来简单介绍一下这个开山鼻祖方法,里面的数学推导我也不做过多的解释
Contributions
我们工作的关键贡献如下:
- 我们设计了一种新颖的深度网络架构,适用于处理3D中的无序点集;
- 我们展示了如何训练这样的网络以执行3D形状分类、形状部件分割和场景语义解析任务;
- 我们对方法的稳定性和效率进行了深入的实证和理论分析;
- 我们展示了网络中选定神经元计算的3D特征,并为其性能发展出直观的解释。
Method
设计来源
- PointNet 架构的设计灵感来源于欧几里德空间中点集所固有的三个主要特性:点的无序性(一个处理 N 个 3D 点集的网络需要对输入的 N! 种排列保持不变),点与点的交互(局部特征),变换不变性(集合变换保持不变)
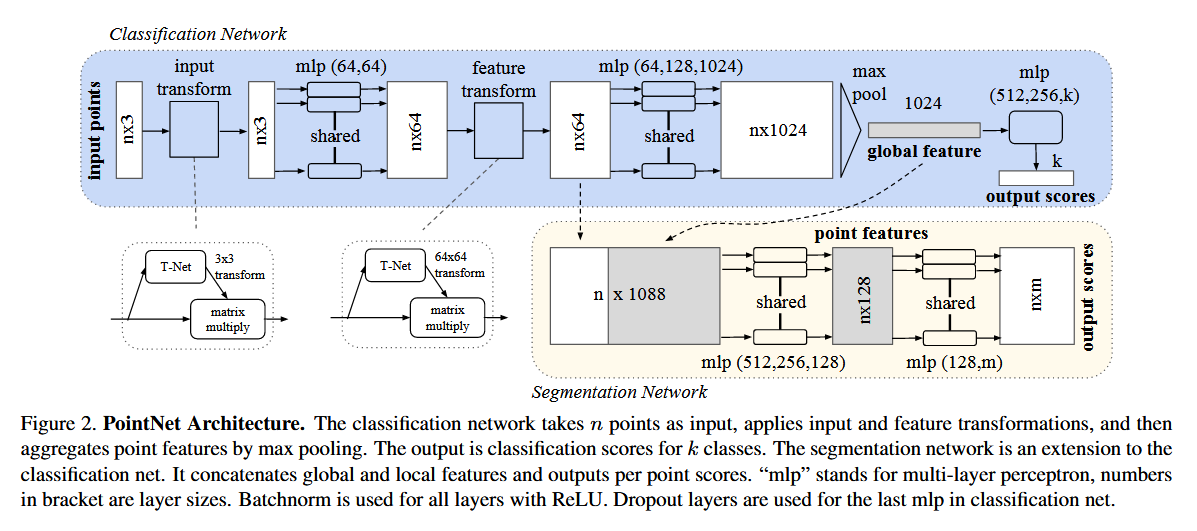
PointNet架构
用于无序输入的对称函数
为了使模型对输入排列不变,存在三种策略 :
- 将输入排序成一个规范的顺序。(×)
高维空间中,并不存在一种对点扰动稳定的排序方式 。因为如果存在这样的排序,就意味着在高维空间和一维实数线之间存在一个保持空间邻近性的双射映射,这在一般情况下是无法实现的 。 - 将输入视为序列来训练 RNN,并通过各种排列来增加训练数据。(×)
RNN可以处理好序列短的,但我们的点云数太多了,效果并不好 - 使用一个简单的对称函数来聚合每个点的信息。(√)
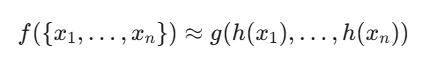
- PointNet做的,就是使用一个神经网络去拟合这个理论上的f函数,这里作者用g表示这个近似的函数,其中x_i表示第i个点,共N维;h函数对应网络中的MLP,而g函数对应网络中的Max Pooling和最后一个MLP的复合。
- 在g保持不变的情况下(使用Max Pooling),学习不同的h,函数复合后就近似不同的f ,这就可以用于多个下游任务。由此看来,完成不同下游任务时基本网络的结构相同,但参数不相同,需要重新针对任务进行训练。
局部和全局信息聚合
- 分类的任务只需要全局信息即可,但是分割需要局部+全局
- 该方法在计算出全局点云特征向量后,它将其与每个点的局部特征进行拼接 。这样,每个点的新特征就同时包含了局部和全局信息 。(就是在n×1088那里)
联合对齐网络
- 前提:如果点云发生某些几何变换,如刚性变换,则点云的语义标注必须保持不变。
- PointNet 通过一个名为 T-Net 的迷你网络来实现对齐 。这个 T-Net 预测一个仿射变换矩阵,并将其直接应用于输入点的坐标,从而将点云对齐到规范空间 。
- PointNet 的第一个 T-Net预测一个 3x3 的矩阵来对齐输入点的坐标,确保所有点云都以一个规范的姿态进入网络,PointNet 的第二个 T-Net预测一个 64×64 的矩阵,来对齐点特征(而不是原始坐标),让网络学习到的抽象特征也保持一致性
- 但是这个维度比较大,特征比较难对齐
- 引入正则化项(类似loss函数,可以更新参数)
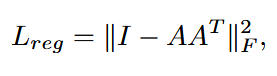
- 来约束特征变换矩阵 A 接近正交矩阵 。这个正则化项使得优化更加稳定,模型性能更好(因为如果A是正交矩阵,它和它的转置矩阵相乘会使单位矩阵,正交矩阵一个基本的特性是,变换后向量的长度不变、夹角不变)
# 第二个t-net产生的损失函数:正则化项
def feature_transform_reguliarzer(trans):
d = trans.size()[1]
I = torch.eye(d)[None, :, :]
if trans.is_cuda:
I = I.cuda()
loss = torch.mean(torch.norm(torch.bmm(trans, trans.transpose(2, 1)) - I, dim=(1, 2)))
return loss
理论分析
通用逼近
- 这里充斥着一些数学公式概念,我不详细介绍可以看这篇博客:经典点云处理网络PointNet论文精读+深度解析!三万字长文带你彻底搞懂-CSDN博客
- 这部分的核心思想是,PointNet 在理论上具有很强的表达能力。它证明了只要网络在最大池化层有足够多的神经元,它就可以“学习”和“逼近”任何对点集进行操作的连续函数。这从根本上保证了 PointNet 能够解决各种 3D 识别任务,因为这些任务(如分类和分割)都可以被视为对点集的连续函数。
瓶颈维度与稳定性
- 这部分是 PointNet 鲁棒性的关键所在。它揭示了为什么 PointNet 能够有效应对点云中的缺失和噪声。
- 最大池化操作的本质是在每个特征维度上选择一个最大值 。这意味着最终的全局特征向量(包含 K 个值)是由点集中的一个或多个点“激活”产生的。作者将这些激活了最大值的点称为关键点集 CS 。
- 由于全局特征是由这些关键点决定的,因此:
- 鲁棒性对抗缺失点:如果你从点集中删除那些非关键点,全局特征向量不会改变,网络的输出也不会变 。
- 鲁棒性对抗噪声点:如果你添加新的噪声点,只要这些噪声点没有产生比现有关键点更高的特征值,全局特征向量就不会改变,网络的输出也不会变 。
- 这说明 PointNet 并不需要关心点云中的所有点,而是学会了通过一个稀疏的关键点集来总结形状的本质。这类似于机器学习中的稀疏性原则,解释了 PointNet 为何对输入扰动、损坏和额外噪声点具有很高的鲁棒性 。实验也表明,这些关键点通常构成了物体的“骨架” 。
评论区