


因为3D生成/重建领域有很多文章都是基于GAN这个结构来重塑网络的,这篇文章我只是看了Method他的思路与code(这里没有官方code库,使用别人复现的code,在评论区)
Method
3D Generative Adversarial Network
3D-GAN基于Goodfellow等人在2014年提出的生成对抗网络(GAN),由生成器和判别器组成:
- 判别器:试图区分真实对象和生成器合成的对象
- 生成器:试图欺骗判别器,生成看起来真实的对象
网络结构
- 生成器G:
- 输出:64×64×64的立方体,代表3D体素空间中的对象G(z)
- 输入:200维的潜在向量z(从概率潜在空间随机采样)
- 判别器D:
- 输入:3D对象
- 输出:置信度值D(x),表示输入对象是真实还是合成的
损失函数
使用二元交叉熵作为分类损失,总体对抗损失函数为: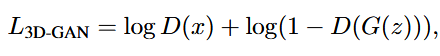
判别器
第一部分:log D(x)
x是一个真实的3D物体 。D(x)是判别器对真实物体x的输出,代表它认为x是“真实”的概率(一个0到1之间的数字)。- 判别器希望
D(x)尽可能地接近1(即100%确定这是真的)。 - 当
D(x)趋近于1时,log(D(x))趋近于0(这是log函数在其定义域内的最大值)。 - 所以,通过最大化这一项,判别器被训练得能给所有真实物体打出高分。
第二部分:log(1 - D(G(z))) z是一个随机噪声向量 。G(z)是生成器根据噪声z创造出的一个“假的”3D物体 。D(G(z))是判别器对这个假物体的判断,即它认为这个假物体是“真实”的概率。- 判别器希望
D(G(z))尽可能地接近0(即100%确定这是假的)。 - 当
D(G(z))趋近于0时,1 - D(G(z))就趋近于1。 - 此时,
log(1 - D(G(z)))也就趋近于0。 - 所以,通过最大化这一项,判别器被训练得能给所有假物体打出低分。
生成器
生成器的目标与判别器完全相反,它希望最小化这个函数的值。 它通过学习创造出越来越逼真的假物体,从而实现这一目标。
- 生成器无法影响函数的第一部分
log D(x),因为它与真实物体x无关。 - 生成器只能影响第二部分
log(1 - D(G(z)))。 - 为了让整个函数值最小,生成器需要让
log(1 - D(G(z)))的值变得尽可能小(即一个绝对值很大的负数)。 - 这只有在
1 - D(G(z))趋近于0时才能实现。 - 而
1 - D(G(z))趋近于0,意味着D(G(z))必须趋近于1。
总结
- 所以,生成器的目标就是让自己生成的假物体
G(z)能够成功骗过判别器,让判别器给它打出接近1的高分。
网络架构设计
生成器:
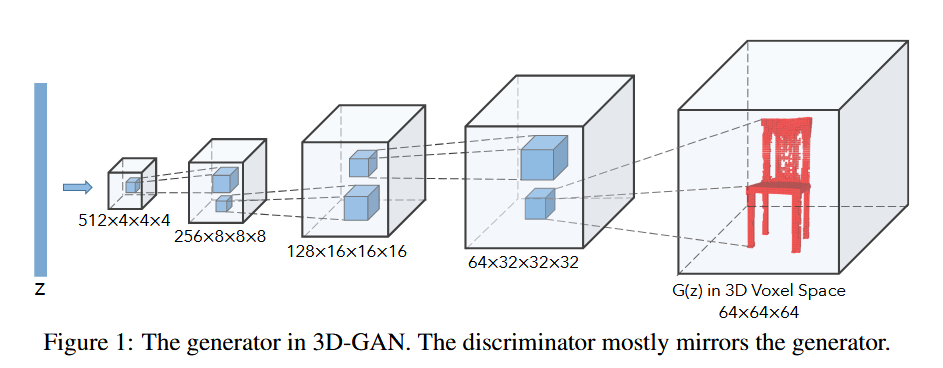
- 5个体积全卷积层
- 卷积核大小:4×4×4,步长为2(这里是转置卷积)
- output_size = (input_size - 1) × stride - 2 × padding + kernel_size
- 包含批归一化和ReLU激活层
- 末端使用Sigmoid层
class Generator(torch.nn.Module):
def __init__(self, in_channels=512, out_dim=64, out_channels=1, noise_dim=200, activation="sigmoid"):
super(Generator, self).__init__()
self.in_channels = in_channels
self.out_dim = out_dim
# 4
self.in_dim = int(out_dim / 16)
# 256
conv1_out_channels = int(self.in_channels / 2.0)
# 128
conv2_out_channels = int(conv1_out_channels / 2)
# 64
conv3_out_channels = int(conv2_out_channels / 2)
# output: [batch_size, 512 * 4 * 4 * 4]
self.linear = torch.nn.Linear(noise_dim, in_channels * self.in_dim * self.in_dim * self.in_dim)
# [batch_size, 256, 8, 8, 8]
self.conv1 = nn.Sequential(
nn.ConvTranspose3d(
in_channels=in_channels, out_channels=conv1_out_channels, kernel_size=(4, 4, 4),
stride=2, padding=1, bias=False
),
nn.BatchNorm3d(conv1_out_channels),
nn.ReLU(inplace=True)
)
# [batch_size, 128, 16, 16, 16]
self.conv2 = nn.Sequential(
nn.ConvTranspose3d(
in_channels=conv1_out_channels, out_channels=conv2_out_channels, kernel_size=(4, 4, 4),
stride=2, padding=1, bias=False
),
nn.BatchNorm3d(conv2_out_channels),
nn.ReLU(inplace=True)
)
# [batch_size, 64, 32, 32, 32]
self.conv3 = nn.Sequential(
nn.ConvTranspose3d(
in_channels=conv2_out_channels, out_channels=conv3_out_channels, kernel_size=(4, 4, 4),
stride=2, padding=1, bias=False
),
nn.BatchNorm3d(conv3_out_channels),
nn.ReLU(inplace=True)
)
# [batch_size, 1, 64, 64, 64]
self.conv4 = nn.Sequential(
nn.ConvTranspose3d(
in_channels=conv3_out_channels, out_channels=out_channels, kernel_size=(4, 4, 4),
stride=2, padding=1, bias=False
)
)
# [batch_size, 1, 64, 64, 64]
if activation == "sigmoid":
self.out = torch.nn.Sigmoid()
else:
self.out = torch.nn.Tanh()
def project(self, x):
"""
projects and reshapes latent vector to starting volume
:param x: latent vector
:return: starting volume
"""
return x.view(-1, self.in_channels, self.in_dim, self.in_dim, self.in_dim)
def forward(self, x):
# [batch_size, 512 * 4 * 4 * 4]
x = self.linear(x)
# [batch_size, 512, 4, 4, 4]
x = self.project(x)
# [batch_size, 256, 8, 8, 8]
x = self.conv1(x)
# [batch_size, 128, 16, 16, 16]
x = self.conv2(x)
# [batch_size, 64, 32, 32, 32]
x = self.conv3(x)
# [batch_size, 1, 64, 64, 64]
x = self.conv4(x)
return self.out(x)
判别器:(其实判别器的部分也被用到PointNet的提取特征的网络中,整体情况都很类似)
- 基本镜像生成器结构
- 使用Leaky ReLU而非ReLU层
- 这里我有个问题,为什么用Leaky ReLU,我问了一下Claude老师,它给出的答案是这样的。
- 在3D GAN的判别器中使用Leaky ReLU是为了确保更稳定的训练过程和更好的梯度流动,这对于复杂的3D生成任务尤为重要
- 判别器需要Leaky ReLU来保持梯度流动以进行准确分类,而生成器使用ReLU更适合生成符合物理约束的3D数据。
- 网络中没有池化层或线性层
# 判别器
class Discriminator(torch.nn.Module):
def __init__(self, in_channels=1, dim=64, out_conv_channels=512):
super(Discriminator, self).__init__()
# 64
conv1_channels = int(out_conv_channels / 8)
# 128
conv2_channels = int(out_conv_channels / 4)
# 256
conv3_channels = int(out_conv_channels / 2)
# 512
self.out_conv_channels = out_conv_channels
# 4
self.out_dim = int(dim / 16)
self.conv1 = nn.Sequential(
nn.Conv3d(
in_channels=in_channels, out_channels=conv1_channels, kernel_size=4,
stride=2, padding=1, bias=False
),
nn.BatchNorm3d(conv1_channels),
nn.LeakyReLU(0.2, inplace=True)
)
self.conv2 = nn.Sequential(
nn.Conv3d(
in_channels=conv1_channels, out_channels=conv2_channels, kernel_size=4,
stride=2, padding=1, bias=False
),
nn.BatchNorm3d(conv2_channels),
nn.LeakyReLU(0.2, inplace=True)
)
self.conv3 = nn.Sequential(
nn.Conv3d(
in_channels=conv2_channels, out_channels=conv3_channels, kernel_size=4,
stride=2, padding=1, bias=False
),
nn.BatchNorm3d(conv3_channels),
nn.LeakyReLU(0.2, inplace=True)
)
self.conv4 = nn.Sequential(
nn.Conv3d(
in_channels=conv3_channels, out_channels=out_conv_channels, kernel_size=4,
stride=2, padding=1, bias=False
),
nn.BatchNorm3d(out_conv_channels),
nn.LeakyReLU(0.2, inplace=True)
)
self.out = nn.Sequential(
nn.Linear(out_conv_channels * self.out_dim * self.out_dim * self.out_dim, 1),
nn.Sigmoid(),
)
# [batch_size, 1, 64, 64, 64]
def forward(self, x):
# [batch_size, 64, 32, 32, 32]
x = self.conv1(x)
# [batch_size, 128, 16, 16, 16]
x = self.conv2(x)
# [batch_size, 256, 8, 8, 8]
x = self.conv3(x)
# [batch_size, 512, 4, 4, 4]
x = self.conv4(x)
# Flatten and apply linear + sigmoid
# [batch_size, 512 * 4 * 4 * 4]
x = x.view(-1, self.out_conv_channels * self.out_dim * self.out_dim * self.out_dim)
# [batch_size, 1]
x = self.out(x)
return x
训练策略
- 标准训练中,判别器通常比生成器学习得更快,因为在3D体素空间中生成对象比区分真假对象更困难。这导致判别器过于强大,生成器难以从中获得改进信号。
- 这里采取了自适应的策略
- 关键策略:仅当判别器在上一批次的准确率不超过80%时,才更新判别器
- 这有助于保持两个网络的训练节奏同步
- 观察到这种方法能稳定训练并产生更好的结果
- 参数设计
- 生成器学习率:0.0025
- 判别器学习率:10⁻⁵
- 批次大小:100
- 优化器:ADAM(β = 0.5)
3D-VAE-GAN
- 这里相当于是个扩展模块,因为GAN的输入是潜在表示向量
- 遵循这一思路,我们引入3D-VAE-GAN作为3D-GAN的扩展 。我们增加了一个额外的图像编码器E,它接收一张2D图像y作为输入,并输出潜在表示向量z 。这个想法的灵感来源于Larsen等人提出的VAE-GAN,它通过让VAE的解码器与GAN的生成器共享权重来将两者结合起来 。
- 因此,3D-VAE-GAN由三个部分组成:一个图像编码器E,一个解码器(即3D-GAN中的生成器G),以及一个判别器D 。图像编码器由五个空间卷积层组成,其卷积核大小分别为{11, 5, 5, 5, 8},步长分别为{4, 2, 2, 2, 1} 。层间有批归一化和ReLU层,并在末端有一个采样器,用于采样一个供3D-GAN使用的200维向量 。生成器和判别器的结构与之前的相同
- 与VAE-GAN相似,我们的损失函数由三部分组成:一个物体重建损失
,一个用于3D-GAN的交叉熵损失,以及一个用于约束编码器输出分布的KL散度损失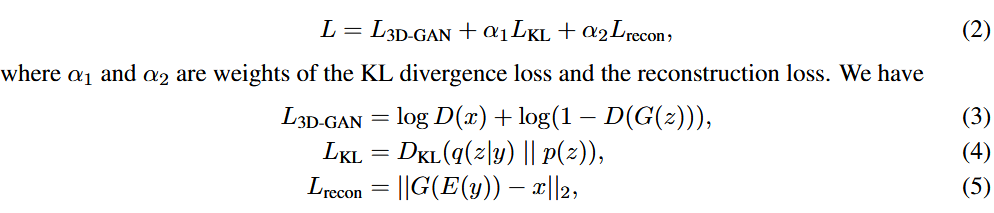
- 训练3D-VAE-GAN需要2D图像及其对应的3D模型 。我们将3D形状渲染在背景图像(来自SUN数据库的16,913张室内图像)上,共72个视角(24个角度和3个仰角) 。我们设置α1=5,α2=10−4,并使用与上个板块中类似的训练策略 。
关于转置卷积
这里其实我一直没搞清,看了几篇文章之后稍微清晰
一文搞懂反卷积,转置卷积 - 知乎
一文搞懂转置卷积的定义、计算和加速 | Zhao Dongyu's Blog
评论区