


点云使用自监督的一般流程
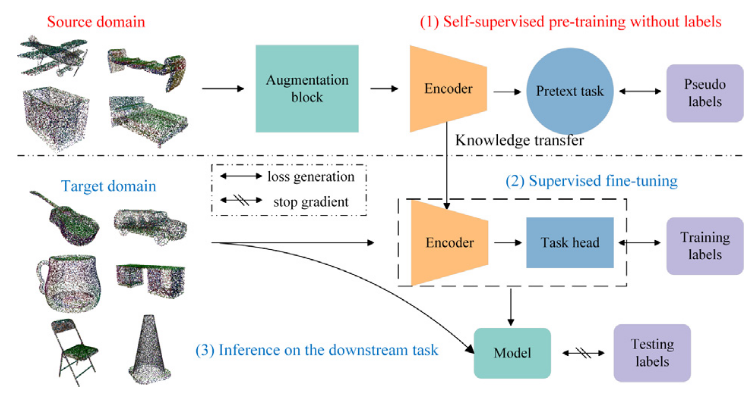
点云自监督学习的流程可以分为三个阶段:
- 预训练阶段(Pre-training):模型通过自构造的伪任务在无标签数据上学习特征;
- 有监督微调阶段(Supervised Fine-tuning):迁移到目标任务,用少量标签训练任务头;
- 推理阶段(Inference):评估模型在下游任务上的表现,验证预训练效果。
- 数据增强:原始输入通过一些易于实现的预处理操作来增强,例如平移、旋转、翻转和添加噪声
- 编码器是一个专门处理点云的深度神经网络,能够从点云数据中逐层提取特征,从而形成**层次化的表示。
- 编码器的结构可能有两种典型思路:
- 逐层下采样(downsampling):比如 PointNet++,通过逐层聚合点云片段,提取不同尺度的特征;
- 局部区域建图(local area association):比如 DGCNN 或 PointCNN,重点建模点与点之间的邻接关系。
- 预任务是整个自监督框架的核心,它的作用是构造“假任务”,来引导模型从无标签数据中自我学习有用的表示。
- 完成预任务后,训练好的编码器就已经具备了提取有用特征的能力。然后可以将这个编码器“迁移”到另一个数据集上(即目标域,target domain),以此来利用其在源域中学到的知识
- 在目标域上,会添加一个任务头(task head),用于执行具体的下游任务(如分类、分割等)。只需少量标注数据就能微调(fine-tune)整个模型,这也正是自监督学习节省标注成本的关键优势。
- 将编码器和任务头连接起来形成完整模型,在测试集上运行(推理)以预测结果。
- 为了验证自监督学习的效果,需要将预训练好的模型在实际的下游任务上进行评估。
基础概念知识
如何评价自监督学习的好坏
- 通过冻结预训练的编码器,并且经过训练来解决分类问题的线性问题,多做几个下游任务进行评估,而不是我们的下游任务(这个更主流一些)
- 微调也可以(进行重新训练),使用预训练模型的权重作为初始状态,在下游任务上进行端到端训练,边进行训练边学习
点云数据的特征
- 点云是离散、无序和无拓扑的3D点的集合
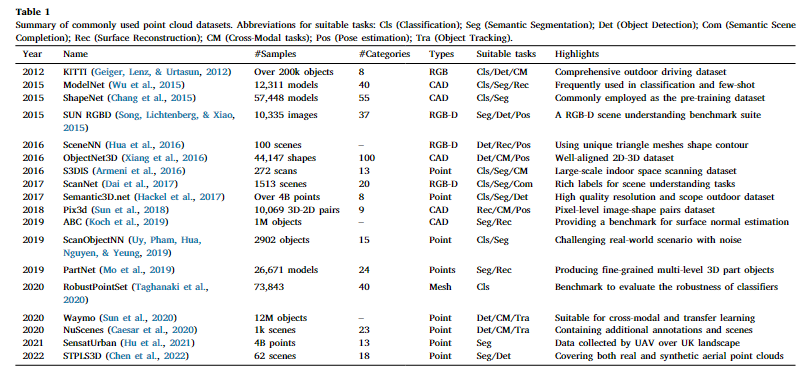
点云数据集
点云数据增强
- 点云数据增强的方法主要有三种:密度/掩蔽、噪声和仿射变换(最后一个可能会改变输入的数据结构)
- 前人工作提出任务相关性被用作评估指标,简而言之就是把一个模型用任务c来预训练后,把它的编码器拿来做下游任务 t,用一个分类器接上去看看效果好不好。如果效果很好,说明这个预训练任务对下游任务是有帮助的,两者相关性就高。
- 验证预训练任务跟下游任务相关性和下游任务的准确性的关系验证:用了两个参数:皮尔逊相关系数(r)和 p值(显著性水平,p<0.05:结果可信),如下图时发现会呈线性关系
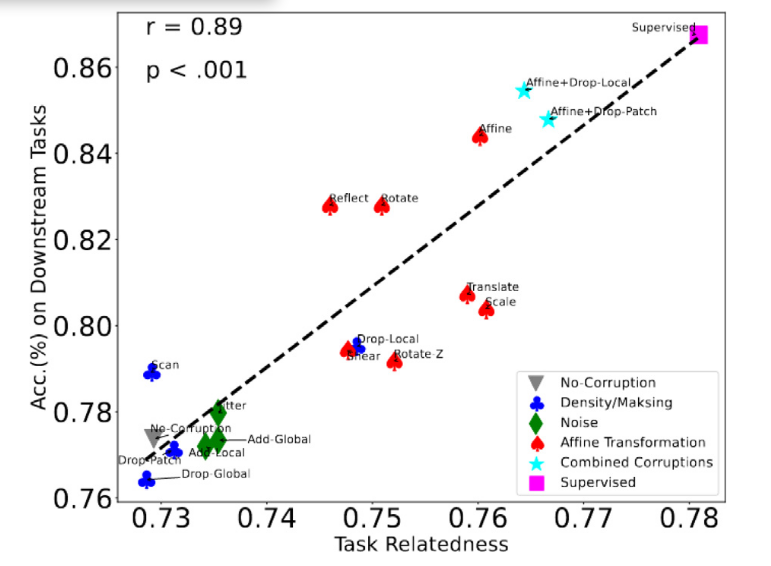
- 上图可以看出:密度/掩码和噪声的数据增强方法在准确性和任务相关性方面对下游任务无效。相反,仿射变换增强了与点云分类的任务相关性,从而提高了准确性。此外,结合仿射变换和掩码的破坏可以接近监督基准的性能。
- 结论:使用基于仿射变换的数据增强方法进行数据增强优于 SSL 预训练
5个点云的流行深度模型
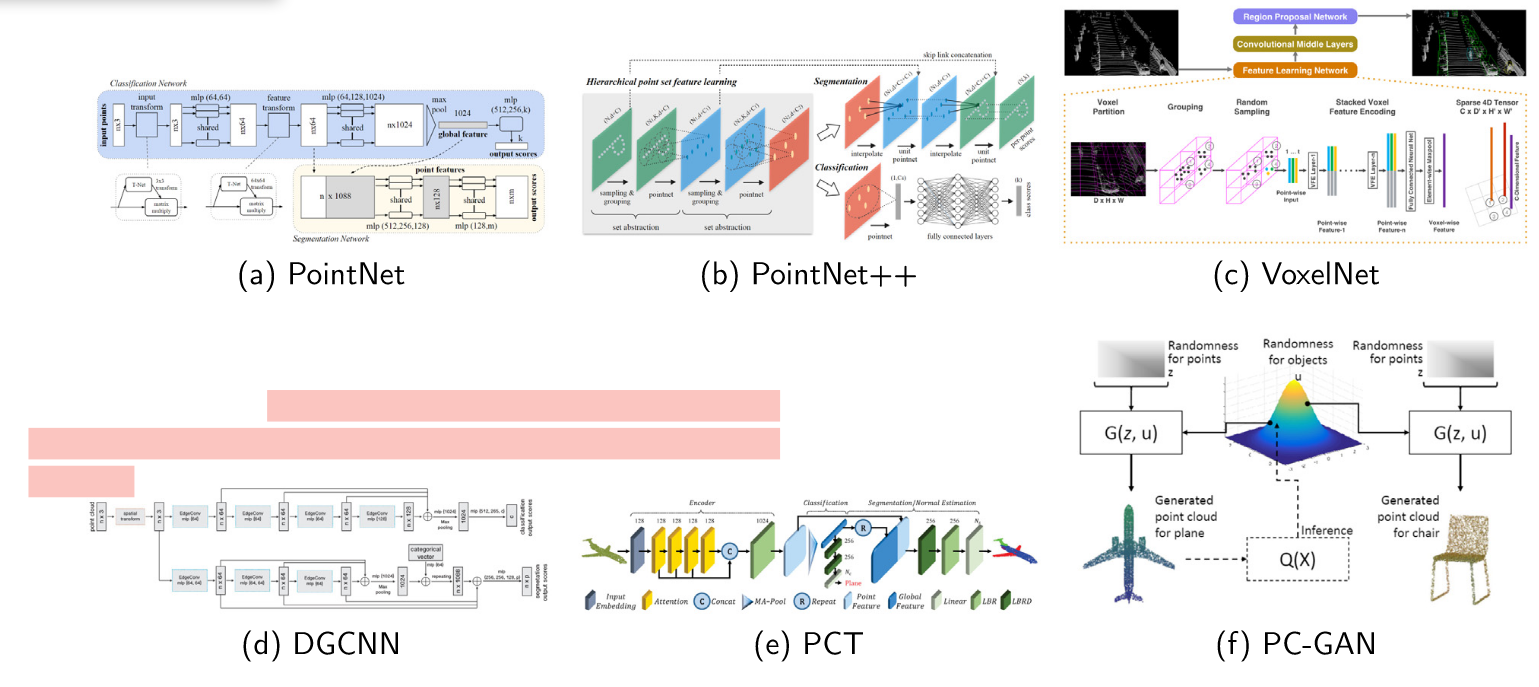
基于点的模型
- 直接在每个点上提取特征,处理点的坐标和特征
- PointNet:它被广泛部署为特征提取器,具有简单而轻量级的网络结构。利用点排列不变性,PointNet将输入点对齐到规范空间(把经过转换额的数据进行标准化统一标准),并通过最大池化等对称函数聚合全局特征。但 PointNet 不考虑点与点之间的空间关系(邻近、连通性等)。所以它无法识别局部细节,比如物体的棱角、纹理
- PointNet++:它采用多尺度(不同半径抓不同范围的局部特征)、多分辨率采样(不同密度的采样)和组合策略(分成不同的patch),将特征从一个层次传播到另一个层次,进一步提高了特征学习能力。此外,结合最远点采样(FPS)和K近邻(KNN)的点云补丁生成策略为后续研究的点云裁剪预处理提供了模板
- 先用FPS选一批“中心点”,再用KNN找每个中心点周围的点组成 patch(一个小组)
基于体素的模型
- VoxelNet:该网络对无序的点云进行分区,并在量化和固定大小的3D结构(体素)中进行特征学习。一个创新是堆叠体素特征编码(VFE)层,它对体素内的点之间的交互进行编码,并掌握描述性外观信息。每个 VFE 层的输出是逐点特征和局部聚合特征的串联,从而更好地捕获局部特征。(让每个点知道“自己”和“所在体素的整体”是什么样的)但是体素构建和量化伪影的昂贵计算限制了模型捕获高分辨率或细粒度表示
基于图的模型
- DGCNN:动态建图 + 边特征编码,该网络对顶点之间的边缘特征进行编码。DGCNN不是直接学习点表示,而是表示点与其边在欧氏空间和语义空间中的相互作用,动态学习图结构,目前也成为了主流的方式
基于transformer的模型
- Transformers 已成为许多领域最流行的架构之一。它们受益于多头自注意力机制,它允许它们捕获点块之间的长期依赖关系并发现隐式区域相关性。
- PCT:点云转换器 (PCT) 是一种专门针对点云的变体,在更远的点采样和最近邻搜索的支持下增强了局部特征提取(这里并不局限于邻居,获得跨区域的上下文信息,更好地区分结构相似但功能不同的区域)
生成对抗网络(GAN)
- 它由两个组件组成:生成器,它生成类似于训练数据的点云,以及区分生成点和实点的判别器。这两个模块是在没有监督的对抗性范式下训练的。
- 目标函数:
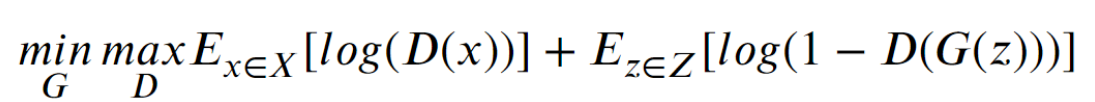
- G是生成器,D是判别器,x是原样本,z是生成器的样本
- PU-GAN(Point Upsampling GAN):把低密度点云“补全成”高密度点云(点云超分辨率)
- PC-GAN(Point Cloud GAN):从随机噪声中生成完整的点云对象(比如一辆车),直接生成三维坐标点集合
- RL-GAN:引入强化学习的策略,引导 GAN 更稳定地训练和生成高质量点云,应用于形状生成或局部补全任务
伪标签
- 伪标签中包含的信息通常被认为是借口任务更可靠和信息量更大的来源,以学习点云表示而不是标签。
- 不同的方法以不同的方式定义伪标签。
- 重构场景:伪标签是点云本身
- 相比之下,伪标签是一个承载收集信息的多维矩阵,通常使用记忆库、在线字典和原型方法等聚类方法生成,表示点云数据集特征的所有或部分的均值和方差。
- 对于在时间点云数据集上预训练的一些基于对齐的预测或基于运动的任务,伪标签是前后许多帧中的位置信息,如位置、姿势和方向。
损失函数
Chamfer距离
- Chamfer距离是一种专门用来比较两个点云集合相似程度的距离度量,是一种重建损失函数。
- 计算方法:
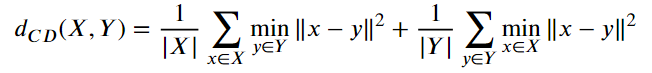
- 对重建点集 X 中的每个点 x,找到原始点集 Y 中距离它最近的点 y,求距离平方,再平均;对Y中的每一个点尽心相同的操作,最后加和,越相似,CD 越小,重建效果越好
InfoNCE损失
它背后的理论基础是最大化互信息(mutual information),也就是让模型区分“真正的搭配”和“随机的噪声”之间的信息差异。
- 计算方法:
![[Pasted image 20250705140156.png]](/upload/Pasted%20image%2020250705140156.png)
- 假设你当前有一个样本 qqq,你想让它更靠近它的“真朋友” k^{+},而远离其他干扰项 k^{1},...,k^{K},这个过程可以看成是一个“(K+1)分类问题”:我们把 q分到一个正确的类k^{+}中,其他都是“错误选项”。
- 最大化分子,最小化分母
点云的自监督学习预训练任务
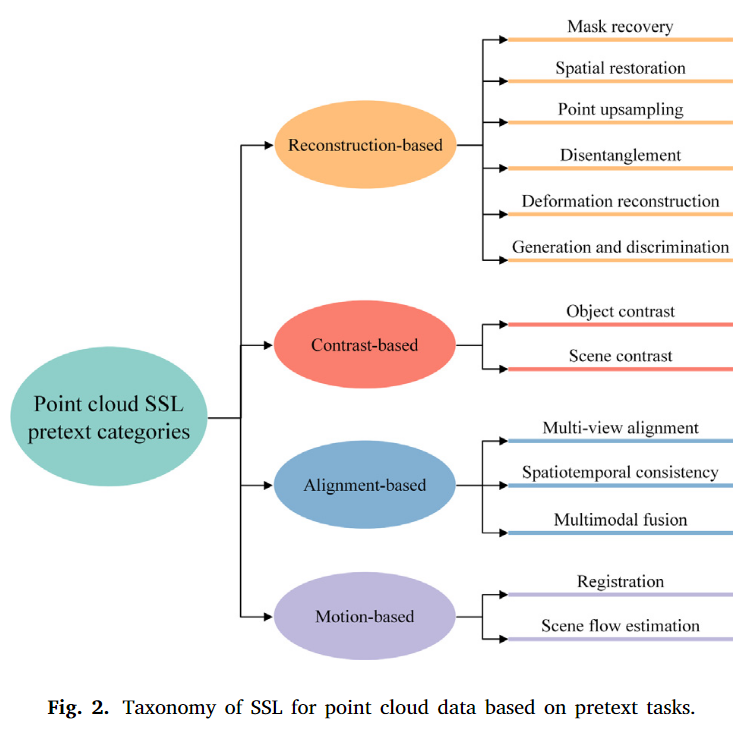
- 把当前的点云自监督学习,按照任务设计方式分为四类:重建类,对比类,对齐类,运动类
基于重构的方法
- 分成6各类别:掩码恢复、空间恢复、点采样、解缠结、变形重建和生成和判别
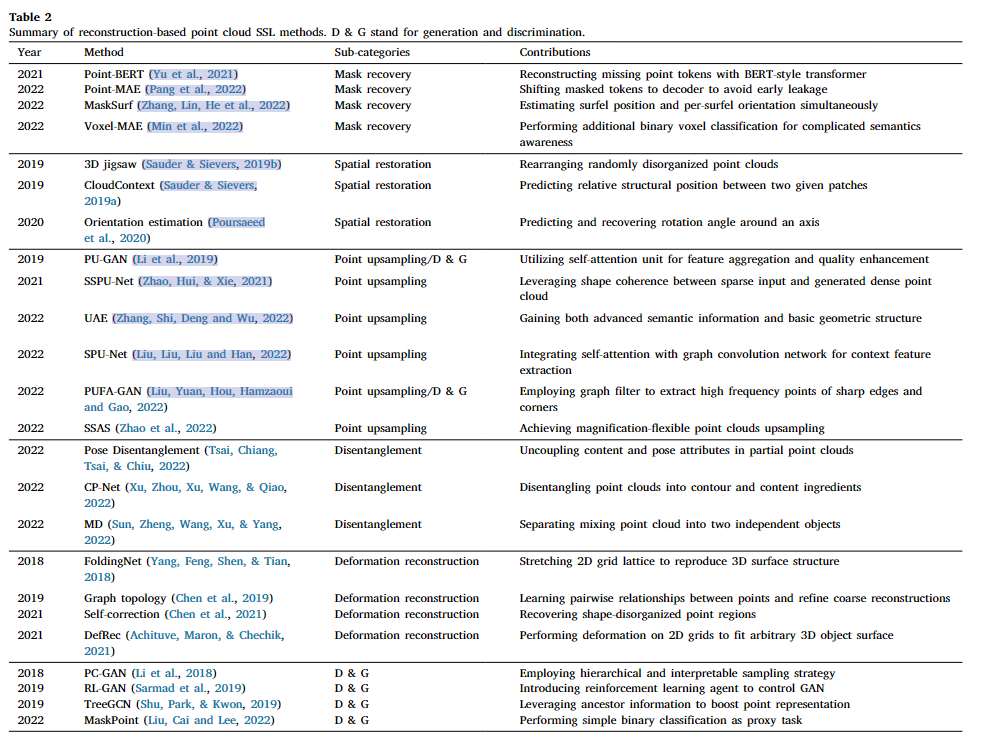
掩码恢复
- 重建的核心思想是屏蔽点云的一部分,并通过编码器-解码器架构恢复这种缺失的部分。与图编码器需要在恢复过程中捕获局部几何结构和区域关系。一般来说,重建越好,学习到的特征越有效。
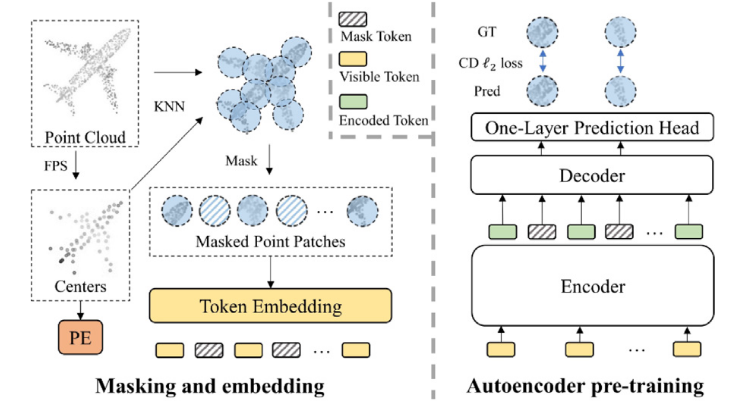
- Point-BERT:离散变分自动编码器 (dVAE) 上设计了一个特定于点的标记器,将patch映射到token以捕获有意义的局部几何模式。输入的一部分被随机屏蔽掉,并训练 BERT 风格的转换器在标记器获得的点标记的监督下重建缺失的标记。然而,分词器应该提前进行预训练,Point-BERT 过度依赖于辅助对比学习和数据增强。
- Point-MAE:使用了标准的 Transformer 作为主干网络,并采用了 非对称的编码器-解码器结构(用一个复杂编码器提取丰富特征,用简单的解码器还原预测遮挡部分),支持较高比例的随机遮挡,改进是遮挡的部分从编码器的输入转移到解码器,减少计算量并且防止了位置泄露
- MaskSurf:为了更好的获取局部特征,双头结构预测每个遮挡的位置和法向量(多了法向量),这样重建效果更好
- Voxel-MAE:将点云转换成体素,并且应用“距离感知”的遮挡策略(根据区域远近,遮挡策略不同,这里是距离越远,mask概率越高),但这个就会存在两个任务,一个重建每个被mask的体素,还要设计二分类任务,判断体素是否包含点云
空间恢复
- 因为点云本身具有很丰富的信息,可以作为自监督的信号出现
- 3D jigsaw:把点云分成几个部分,随机打乱顺序,识别打乱后原本应该在voxel表格中的哪个位置(体素的ID)
- CloudContext:预测两个点云块之间的空间关系
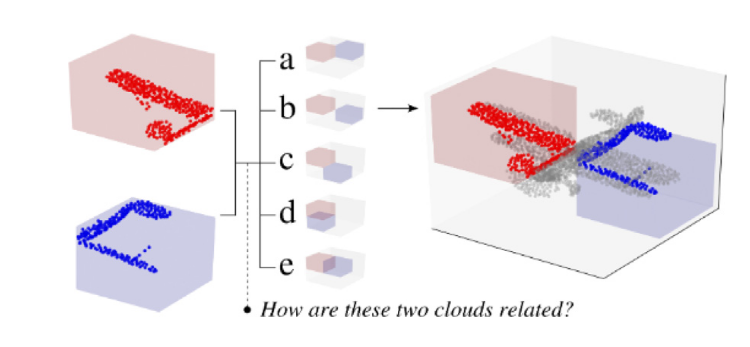
- 强制预训练模型从六个类别中估计两个给定点云之间的空间相关性。它利用了点云的先天属性,因为它们不受离散网格的限制。
- Orientation estimation:“姿态估计”是一种简单但有效的自监督任务,用于帮助模型学习点云的空间结构信息(比如物体朝向、上下方向、整体形状等),通过矩阵乘法来完成矩阵旋转,让模型预测旋转了多少度。不需要标注,对整体形态要求很高。
点上采样
- 点云上采样是将稀疏、带噪声且分布不均的点云,转换成稠密、完整且高分辨率的点云的过程,可以更好的捕捉隐式几何特征
- PU-GAN:第一个基于生成对抗网络(GAN)的自监督点云上采样方法;从**潜在空间(latent space)(低维但包含几何语义的隐空间向量)生成多样的点云分布,针对点云的局部patch做上采样,增强点的密度和多样性。
- 生成器内部有一个“上采样-下采样-再上采样”的模块,用来有效扩展点的特征表示;同时引入自注意力机制(self-attention),用来提升特征聚合的质量,使生成的点云更精细、更均匀。
- 判别器不仅判断生成点云是否逼真,还关注点的分布均匀性;损失函数由多部分组成,包括:对抗损失(adversarial loss)促进生成点云更真实;均匀性损失保证点云点均匀分布;重建损失确保生成点云保持形状的准确性。
- 上采样自动编码器(UAE):采用经典的 AutoEncoder 架构(编码器-解码器),加上专门设计的上采样机制,学习怎么从稀疏点云补全形状。
- 设计了编码器对下采样点云进行逐点特征提取,设计了上采样解码器重建具有偏移注意的原始密集点云来细化全局形状结构(生成的新点不是复制,而是加上一个偏移量,让它们围绕原点合理分布)
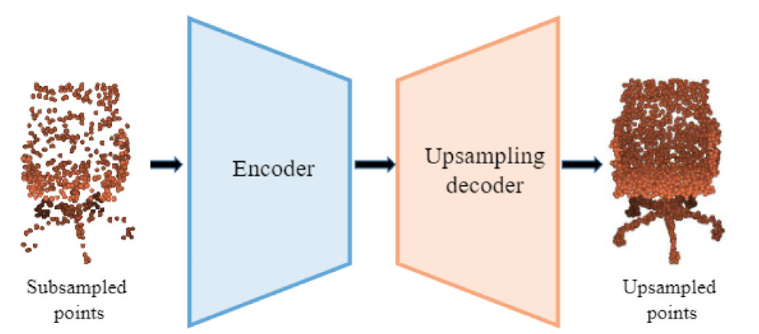
- 输入点云通过随机抽样策略进行二次采样,然后馈入编码器以提取逐点特征
- SPU-Net:“粗到细”(coarse-to-fine)的点云重建/上采样方法(先轮廓再细节)把GCN和自注意力机制结合(局部结构和远程依赖)为了生成稠密点集,SPU-Net 不直接预测 3D 坐标,而是先在局部 patch 上生成一个 可学习的二维网格(grid);然后再通过映射,将这个 2D 网格拉伸成 3D 空间中的点。
- SSPU-Net:强调稀疏点云和上采样后点云在形状上的一致性,- 把生成的点云从不同角度“投影成图像”;后和原始点云的渲染图做对比;加一个图像级别的损失,例如像素误差、边缘对齐等;
- PUFA-GAN:一个频率感知的点云上采样框架,让生成的点云在边缘、拐角这些细节区域更加清晰、准确。使用图滤波器(graph filter)来提取“高频点” —— 比如点云中表示物体边缘、角落、细节轮廓的点。判别器会判断这些区域补得像不像;促使生成器学会在这些细节上补点更精确、更均匀。
- SSAS:摆脱固定的上采样因子限制,它是一种具有放大灵活上采样策略的自监督任意尺度(SSAS)框架
- 设物体的表面存在一个隐式曲面(implicit surface);对于每个原始点(称为 seed point),它估计该点到这个隐式曲面的投影位置;然后生成的点就放在这个投影点附近 —— 更贴合真实表面。
- 设计了两个函数:一个预测每个点往哪个方向投影(方向函数);一个预测要移动多远才能投影到表面(距离函数);
特征解耦
- 我们希望模型分开学习两种东西: 几何属性(结构、姿态、轮廓) 语义属性(类别、本质含义),解耦的目标是提升整体能力,防止信息混淆。
- Pose disentanglement :把“内容”和“姿态”解耦开来学习。使用两个编码器分别学习内容和多视图姿势,其中获得的姿势表示应该预测视角(比如:30°,侧面)并与来自另一个特定视图的内容配合
- CP-Net:它将点云分解为轮廓和内容成分。在轮廓分量上利用简洁的轮廓扰动增强单元,并保留点云的内容部分(让模型更专注于语义内容)因此,自我监督器能够连接内容组件以进行高级语义理解,利用“内容部分”去理解物体的类别或本质功能
- MD:混合两个不同形状,再解耦重建。
- 示意图
![[Pasted image 20250703100228.png]](/upload/Pasted%20image%2020250703100228.png)
- 两个输入点云分别减半并混合成一个混合对象,馈送到编码器,以挖掘几何感知嵌入。采用“擦除”操作同时从原始输入点云中获得二维投影。实例自适应解码器 接收嵌入和两个部分投影作为输入,以将混合形状分解为原始两个点云。倒角距离用于衡量生成的点云与原始点云之间的重建误差。
- 示意图
形变重建
- 点云变形是现实世界数据扫描中常见的现象,通常是由对象失真、传感器噪声或外部遮挡引起的。已经发现,SSL通过从人为变形的点云(例如添加高斯噪声或局部平移)重建原始点云,使模型能够获得几何感知和上下文感知。
- Self-correction:自我修复点云形状的预训练任务
- 提出一种方法:
![[Pasted image 20250704160242.png]](/upload/Pasted%20image%2020250704160242.png)
- 先使用一个破坏模块,得到一个变形的点云,之后送入一个编码器,提取结构感知特征,后面接了两个任务头:判别头(识别哪些是被破坏的)和 分割头(分类或者修复操作)恢复原状,最后编码器来迁移到其他任务中
- 提出一种方法:
- DefRec:第一个将形变重建方法用于“领域适应”的点云自监督学习工作(可以在不同领域迁移)。通过学习如何把被扰乱的点移回原位,学习点云的潜在结构信息这些结构信息对不同领域是稳定的。模型学到的表示是基于更底层的几何规律,更好迁移
- FoldingNet:从一个固定的二维网格出发,然后通过输入点云提取到的特征向量做一种虚拟力量,来牵引二维网格形成三维的形状,解决了点云无序的问题。
- Graph topology :将图拓扑推理(学习连接关系)和图过滤模块(增加结构一致性和局部特征表达)集成到解码器中,以学习 3D 点之间的成对关系并细化粗重建,用图结构中的“图平滑性(图中相邻节点的特征值应该尽量相近)”作为先验,比传统的欧式空间距离更好;它能更有效地建模点云的真实几何结构,提升重建精度和自监督表示能力。
生成与判别
- “生成与判别”类自监督任务借助 GAN 的思想,让生成器学会重建真实点云,让判别器学会识别点云真假,在这种对抗训练中,模型逐步掌握了结构理解和表达能力,最终能泛化到其他点云任务中
- PC-GAN:采用受贝叶斯(通过先验(对数据预期)和似然推断(观察的数据)后验的概率)和隐式生成模型启发的分层和可解释的采样策略来解决判别器上缺失约束的问题。
- RL-GAN:设计了RL agent来控制GAN模型,从“噪声和不完整的输入”里提取隐式(潜在)表示(更细节的表示),生成“高质量且完整”的点云数据。
- TreeGCN:引入树结构的图卷积网络(TreeGCN)作为生成器。
利用“祖先节点的信息”,更好地理解点与点之间的关系。相比传统GCN用“邻居节点特征”,树结构计算更高效。 - PU-GAN) 和 PUFA-GAN都采用了基于 GAN 的模型来生成密集且均匀的点云,具有创新的模块用于特征聚合增强和高频点过滤
- MaskPoint:它是一种基于 Transformer 的预训练方法,结合了“遮挡(mask)”和“判别(discrimination)”两种技巧,目标是让模型学会更好理解点云的结构。
![[Pasted image 20250704164327.png]](/upload/Pasted%20image%2020250704164327.png)
- 原始的完整点云分为 90% 的掩蔽部分和 10% 的可见部分。两种类型的查询,其中真实是从掩码点云中采样的(真是但被隐藏),而假来自随机噪声,两种点被馈送到解码器进行分类。在判别过程中,模型需要从小的可见部分推断出完整的几何图形。
总结
- 基于重建的自监督学习方法能让模型学到更细致、更有意义的点云特征,但它们通常需要很大的计算和存储资源。
基于对比的方法
- 对比学习是一种流行的SSL模式,它鼓励增强相同的输入以获得更可比较的表示。一般方法是通过各种数据增强技术扩展输入点云(锚点)的视图。希望这些来自同一个输入的不同增强版本在模型的特征空间里越相似越好(称为正样本),同时希望不同输入的数据特征表现得尽量不相似(称为负样本)。
- 具体方法
![[Pasted image 20250704165216.png]](/upload/Pasted%20image%2020250704165216.png)
对象对比
- 对象对比是传统对比学习的一个范式,它通过对整体或大块的点云对象做增强和判别,帮助模型理解和学习全局的几何和语义信息。
- Info3D:目标是让模型学到对旋转不敏感的点云表示,也就是说,旋转物体后,模型的理解不变。方法是最大化整体3D对象与它的局部部分(chunks)以及几何变换版本之间的互信息(衡量两个变量“相关度”的指标),把整体和局部、变换前后都看作紧密关联的,即保持局部和整体信息的一致性。
- AFSRL:该框架同时施加数据增强(旋转缩放)和特征增强(特征变换,特征融合),构建稳定且不变的点云嵌入。获取增强对之间的对应关系(利用点的索引或基于空间距离的匹配,确定增强前后的点是对应的),并在增强过程中保持不变语义。
- Contrasting and clustering:通过连续解决部分对比和对象聚类(类似比较之后再聚类分类)任务来捕获优越的点嵌入(通过对比学习,让模型学会区分点云中不同局部结构的差异,捕获细粒度的局部特征表示,在全局尺度上,通过聚类对点云进行整体的结构抽象,学习到有意义的全局对象类别或形状模式。)
- Hard negative:一个自对比(self-contrastive)范式,利用同一个点云内部的自相似点云片段(patches),促进对局部形状和全局上下文特征的学习。
![[Pasted image 20250704175237.png]](/upload/Pasted%20image%2020250704175237.png) 选择Patch A 作为锚点,对称部分 Patch D 是正样本。{Patch}B 和 C 是负样本,其中 Patch B 很难区分,因为它与锚点的比较相似性
选择Patch A 作为锚点,对称部分 Patch D 是正样本。{Patch}B 和 C 是负样本,其中 Patch B 很难区分,因为它与锚点的比较相似性- 图展示的内容基于点云的非局部自相似性(nonlocal self-similar property),即点云的某些区域在经过仿射变换(旋转、缩放、平移)后,区域的几何结构保持不变。这些自相似的点云片段被视为正样本,其他不相似的片段则作为负样本,这里的相似性是根据推断得到的相似度分数来判断,还会采样“难负样本”(hard negative samples),即在表示空间中距离正样本较近的负样本,这样做能让模型学得更具判别力和表达力的特征表示。
场景对比
- 关注整个场景,比如一间房间、一条街道,学习场景中更广泛的环境信息和邻近关系,更贴近真实环境
- 域差距指的是:仅仅对单个物体建模,难以捕获复杂场景的整体全局信息
- PointContrast:它的骨干网络是 稀疏残差 U-Net(用来高效地处理稀疏的点云数据),提取出来稠密高质量的特征表示
![[Pasted image 20250705084717.png]](/upload/Pasted%20image%2020250705084717.png) 对比在两个变换(从不同视角扫描得到)后的点云之间的点级进行,其中正样本是匹配点,负样本是两个视图之间的不匹配点。
对比在两个变换(从不同视角扫描得到)后的点云之间的点级进行,其中正样本是匹配点,负样本是两个视图之间的不匹配点。- 扫描之后可以加入一些刚性变换(人为增加难度),对比损失被定义为缩短匹配点之间的距离,扩大两个重叠部分扫描不匹配点的距离,可以学到局部特征还可以很好的适用于各种下游3D任务
- 缺点:忽略了更大的空间结构(点的相对位置,相对姿态,空间关系)
- Contrastive Scene Contexts:其不仅仅比较点和点,还把空间信息考虑进来,利用了ShapeContext 描述子,把场景划分成多个区域(region),在每个区域内部做对比学习——不仅比点本身,还比这些区域内的空间结构特征。**只用 0.1% 的点标签,就能达到几乎和全监督一样的效果!
- CoCoNets:通过将RGB-D(彩色图像的深度图)图像映射到3D点场景和优化视图(多角度对比)对比预测来推断潜在的场景表示,训练模型让相同场景不同视角的表示接近,不同场景的表示远离
- P4Contrast:也是利用RGB-D 双模态,把图像中的像素(Pixel) 和 点云中的点(Point) 一一对应;然后让“相同位置的像素点”和“对应的3D点”在特征空间中靠得近;“不匹配的点对”作为负样本,也可以灵活挑选难负样本(hard negatives)。
- DepthConstrast:规避了点对应关系的需要,而是将Instance Discrimination实例判别方法(就是把每张深度图都当作一个独立类别),应用于深度图结合动量编码器(主编码器不断更新,动量编码器是主编码器的平滑版本)来改进几何感知,让训练更稳定更鲁棒
总结
内存消耗高,是当前这类方法面临的重要技术难题
基于对齐的方法
- 点云表示通常在时间流、空间运动、多视角摄影等方面对变换是不变的,主要分为三类对齐方式。
![[Pasted image 20250705092316.png]](/upload/Pasted%20image%2020250705092316.png)
多视图对齐
- 先把点云转成2D图像,再用图像领域的成熟技术来学特征,可以把点云投影成若干个2D图像,可以用图像网络和自监督技术来提取特征
- Info3D:学习一种对旋转不敏感(rotation-insensitive)的点云表示。将一个3D对象划分成多个小块,让模型学会整体和局部之间的信息要一致(mutual information互信息通常是“一个局部区域”包含了多少“整体信息”要最大化)
- OcCo:结合遮挡恢复屏蔽和恢复摄像机视图中被遮挡点的思想,以获得更好的空间和语义属性理解。(认为再一个视角拍摄点云后遮挡一部分点)
- Multi-view stereo:生成初始深度图作为伪标签(pseudo-labels),通过多视图深度融合反复优化自监督信号,将点云中的每个点和像素进行了对齐,实现跨模态的一致性
- Cross-view:该框架利用跨模态和跨视图对应来同时学习三维点云和二维图像特征表示,除了 2D-3D 一致性之外,对比概念还被用于跨视图对齐,该对齐缩短了对象内距离,同时最大化不同渲染图像的对象间差异
- 跨模态和跨视图对应关系的示意图
![[Pasted image 20250705093956.png]](/upload/Pasted%20image%2020250705093956.png)
- 分别从相同的网格输入中采样3D点云对象和相应的多视图渲染图像对。通过维持多视图和跨域表示之间的对齐,将不同视图之间的关系捕获为监督信号。
- 跨模态和跨视图对应关系的示意图
- Multi-view rendering:双分支(2D,3D),不仅同意细粒度的像素点局部表示,而且通过利用知识蒸馏鼓励2D-3D全局特征分布尽可能接近。
- Graph matching:一个基于图的框架,探索了两个域之间的局部特征对齐。在两个域中都会动态构建局部特征图(节点表示局部特征,边相似性),接着通过最优传输方法来生成两个域之间的匹配对,此外,考虑到不同类别之间的特征相关性,设计了一种基于类别指导的对比损失函数(category-guided contrastive loss),用于提取目标域中的判别性信息。
时空一致性
- 时空方法更关心某些点云帧前后的远程空间和时间不变性,即 4D 数据(XYZ 坐标+时间维度),以捕获动态序列的内在特征。
- Order prediction:用于动态点云数据的自监督时间特征学习方法,通过对采样和未组织的点云片段的时间顺序进行排序,在动态点云数据上获得有效的时间嵌入,对一些静态点云帧进行均匀采样和无序处理,然后由4D CNN处理,在未注释的、大规模的、顺序的点云动作识别数据集上将被破坏的片段恢复到正确的顺序。
![[Pasted image 20250705100054.png]](/upload/Pasted%20image%2020250705100054.png)
- 第一行是来自连续点云序列的均匀采样点云片段。然后这些剪辑被随机打乱,然后输入第二行的4D CNN,以学习人类行为的动态特征,以自我监督的方式预测原始时间顺序。
- STRL:灵感来自于自监督学习方法 BYOL,一个双分支结构: 一个叫 online network(在线网络),一个叫 target network(目标网络)训练时的任务是:
- 在线网络负责去预测目标网络对一个时间相关的点云输入的表示(特征向量)
- 举个例子:给模型两段时间上相邻的点云(比如第3帧和第4帧),它要学会从第3帧中“推断出”第4帧的特征。
- 目标网络的输入是经过随机空间变换(如旋转、缩放等)的数据,这样训练的目的就是让模型能从不同的角度、不同的时间帧中提取出不变的时空上下文特征
- Future prediction:考虑到训练和推理时间,提出创新的 3D 时空卷积编码器-解码器神经网络,该网络由更少的参数组成,以预测未来的点云场景。这样的轻量级模型将多个距离图作为输入,在多个未来步骤中估计即将到来的图像和每个点的预测评分,以便可以同时捕获空间和时间场景信息
多模态融合
- 自动驾驶中的算法,不仅需要一个传感器工作得好,而是要求车上各种传感器之间高效协同工作,比如:相机(camera):拍出彩色图像,有纹理信息、语义线索(如红绿灯、人行道)激光雷达(LiDAR):提供准确的3D空间结构信息,比如物体距离、形状,把这两者结合起来,能让模型在做 3D目标检测效果更好
- PointPainting:是一种顺序融合方法(sequential fusion):
它把 LiDAR点 投影到 语义分割后的图像 上(即识别过“这是人”、“这是车”的图像),然后根据图像结果给每个点云点打上语义类别分数标签,这样涂色后的点云,就可以作为输入喂给任何点云检测网络,帮助它做更准确的 3D 检测,整合鸟瞰图和相机视图巧妙地解决了深度模糊和尺度模糊的局限性。 - PointAugmenting:采用基于 PointPainting 的后期融合机制,用包含丰富前景提示和更大感受野的高维 CNN 特征(把 CNN 网络提取出的高维图像特征(feature maps)直接用来装饰 LiDAR 点)替换分数以强调精细的细节,此外,设计一种简单而有效的跨模态数据增强将虚拟对象(合成的人或者车等)粘贴到图像和点云中,用于相机和激光雷达之间的对齐。
- DeepFusion:在特征级别提出了一种端到端跨模态融合,重点关注一致性改进,直接在图像特征和点云特征之间建模它们的相互关系,而不只是装饰点。
![[Pasted image 20250705103706.png]](/upload/Pasted%20image%2020250705103706.png)
- (a) 传统跨模态范式:直接在输入层面(input-level)将摄像头提取的特征“装饰”到 LiDAR 点云点上。比如给每个 LiDAR 点附加一个来自图像的语义标签或者特征向量。融合比较浅,属于拼接或附加信息,后续网络还是以点云为主进行检测。
- (b) DeepFusion:先分别用各自的编码器提取图像特征和 LiDAR 特征(两边独立编码),然后通过引入了一个名为 LearnableAlign 的块的跨注意力机制做深度特征融合,保证图像和点云之间的特征一致融合更深入、动态,模型能捕捉跨模态长距离相关信息,提升识别和定位能力。
- Open vocabulary 3D detection:一个无需人工标注的开放词汇3D目标检测框架。这个检测器通过文本提示(text prompting),连接文本和点云的表示,实现对3D物体的定位和分类。
- CLIP2:文本-图像-点云三模态的实例级对齐模型,它能从复杂场景中构建良好对齐的三模态代理表示(text-image-point proxies),大幅提升了零样本和少样本3D识别任务的性能。
简单说,CLIP2让模型可以理解从未见过的类别,只靠文本描述就能识别3D物体。
- ULIP:提出了另一种文本-图像-点三元组预训练框架,将3D嵌入与预对齐的图像-文本特征空间对齐,以获得统一的表示。因此,该模型能够实现跨域下游任务,例如零样本 3D 分类和图像到点检索。
总结
人们认为多模态融合在进一步的自动驾驶发展方面具有巨大潜力。然而,它还必须解决模态之间数据冲突的挑战以及更合适的融合解决方案。
基于运动的方法
- 连续的点云帧(比如来自激光雷达的扫描序列)包含了丰富的几何形状变化和物体运动模式(kinematics), 这些信息并不是静态地表现出来的,而是隐藏在物体或场景的运动中,从点云序列中自动捕捉空间变化中蕴含的运动特征, 即不需要人工标注,仅通过观察点云帧的时空变化,理解物体是怎么动的。
![[Pasted image 20250705110151.png]](/upload/Pasted%20image%2020250705110151.png)
配准
- 把两个点云(比如来自不同时间或视角的扫描)对齐到同一个坐标系下,也就是说,找到一个刚性变换,让它们能重叠起来,形成一个整体。
![[Pasted image 20250705110416.png]](/upload/Pasted%20image%2020250705110416.png) 在寻找最优的旋转 𝑅 和平移 𝑡,使得变换后的点云 𝑋 和点云 𝑌 的特征差异最小。
在寻找最优的旋转 𝑅 和平移 𝑡,使得变换后的点云 𝑋 和点云 𝑌 的特征差异最小。
- 通过自监督训练特征提取网络,不依赖精确的点对匹配,也不需要标签
- PRNet:一种部分到部分的配准方法,可以迭代地进行从粗到细的细化。基于协同上下文信息,该框架归结为一个关键点检测任务,旨在从两个输入点云中识别匹配点
- Part mobility:一种部分移动性分割方法来理解动态对象的基本属性。原始输入不是直接处理顺序点云,而是通过连续帧之间的点对应关系转换为轨迹,以获得刚性变换假设
- SuperLine3D:从点云中提取出结构性更强、更鲁棒的线段(line segments)特征,而不是单个离散点,这些线特征可以用来完成大尺度点云配准,而且不需要任何人工标签或先验信息(真正自监督),该分割模型能够在任意尺度扰动下获得精确的线表示。
- DVDs:点云子区域中独特的局部几何结构可以在不同点云之间形成可靠的语义“锚点”;即使整体发生刚性变换(旋转、平移),这些小的几何形状在两帧点云中仍然存在;所以,如果我们能从这些重复出现(co-occurring)的小局部结构中提取表示,可以显著提升点云的特征学习能力。
- 同时学习:局部点嵌入(local embedding):关注每个点或局部 patch 的几何结构;全局点嵌入(global embedding):捕捉整个点云的形状、结构、空间信息;
![[Pasted image 20250705120234.png]](/upload/Pasted%20image%2020250705120234.png) 输入由刚性变换前后的两个点云组成,其中公共点分量用于训练编码器进行全局和局部表示学习。
输入由刚性变换前后的两个点云组成,其中公共点分量用于训练编码器进行全局和局部表示学习。 - 输入的是:两个点云中结构相似的小区域(local regions),这些区域是在配准或不同视角下重复出现的。网络试图从这些区域中提取出潜在的几何信息,来学习“有意义且稳定”的表示。DVD用了一种 局部一致性损失(local consistency loss) 来:约束同一结构在两个点云中的嵌入特征要靠近;提高特征对刚性变换的鲁棒性。为了进一步增强模型转换感知能力,将重构和正常估计作为辅助任务,以便更好地对齐。
- 同时学习:局部点嵌入(local embedding):关注每个点或局部 patch 的几何结构;全局点嵌入(global embedding):捕捉整个点云的形状、结构、空间信息;
场景流估计
- 对于点云,其目标是通过计算场景连续激光雷达扫描之间的密集对应关系来估计物体的运动。点的变化可以表示为3D位移向量来描述场景流的运动。
- PointPWC-Net:引入了成本量(在两个点云之间对点对进行匹配的“成本”评估结构。)的概念,并提出了一个可学习的基于点的网络,通过对点对进行离散化,可以降低计算复杂度,避免对所有点对的全连接计算。此外,还采用了一种有效的上采样策略和包裹层。
- Just go with the flow:通过基于最近邻和循环一致性两个损失函数,进行训练
![[Pasted image 20250705121314.png]](/upload/Pasted%20image%2020250705121314.png)
- 预测流(图中绿色点)代表从当前帧 t 出发,点向未来帧 t+1 移动后的预估位置。伪真值(红色点)是未来帧中对应点的估计位置(可以是从数据中自动生成或由模型辅助生成的)。
- 最近邻损失鼓励绿色点与红色点在空间上越接近越好,让预测的动作更合理。
- 从未来帧 t+1 的预测点(绿色点)出发,预测逆向的流(运动),流回当前帧 t。这时,预测点(绿色)应该能回到原始帧(蓝色点)的位置。
- 循环一致性损失惩罚这种前后流不一致的情况,保持时间连续性和合理性。
- Self-Point-Flow:不仅仅使用点的 3D 坐标,还利用了表面法向量,颜色生成伪标签,并将伪标签生成问题制定为最优传输问题。它利用随机游走模块通过施加局部对齐来细化注释质量。
总结
发现相应的关系并不能保证准确,有时虚假的对应关系可能会导致退化的解决方案和性能。
下游任务
- SSL的主要目标之一是预训练骨干网并将其转移到解决下游任务中的问题。介绍了四个常用的下游任务,并提供了广泛使用的评估指标
对象分类
- 要求模型为给定的点云对象输出最可能的标签,以评估预训练模型的整体语义感知。
- 该任务的两个常用指标是总体准确度 (OA) 和平均类别准确度 (mAcc)。OA 是正确分类的对象与对象总数的比率,mAcc 是每个类的准确度的平均值。对象分类可以根据任务设置分为三种:
- 小样本学习:𝑛-way,𝑚-shot,即从数据集中随机选取 n 个类别,每个类别随机选 m 个样本用于训练。考察再极少标注样本情况下的泛化能力
- 微调:预训练的特征提取器作为初始下游主干编码器,整个网络以有监督的方式重新训练,标签来自下游数据集
- 线性分类:冻结预训练特征提取器的参数(停止梯度反传),保持其特征不变。在预训练特征基础上训练一个简单的线性分类器(如线性层或Logistic回归)进行分类。
- 小样本学习:𝑛-way,𝑚-shot,即从数据集中随机选取 n 个类别,每个类别随机选 m 个样本用于训练。考察再极少标注样本情况下的泛化能力
![[Pasted image 20250705123335.png]](/upload/Pasted%20image%2020250705123335.png)
![[Pasted image 20250705123706.png]](/upload/Pasted%20image%2020250705123706.png)
![[Pasted image 20250705123957.png]](/upload/Pasted%20image%2020250705123957.png)
部件分割
- 对一个对象的点云进行更细粒度的划分,区分并分割出对象的各个组成部分。这项任务要求模型不仅能理解整体物体类别,还要更精准地提取局部的点级别特征,区别不同部件。点云部分分割的流行评估标准是平均交并比(mIoU),它计算所有类别 (mIoUC) 或所有实例 (mIoUI) 中预测和地面实况部分标签与两者的并集的交集之比。下表总结了基于 SSL 预训练模型的 ShapeNetPart 数据集上的部分分割结果
![[Pasted image 20250705124755.png]](/upload/Pasted%20image%2020250705124755.png)
语义分割
- 对点云中的每个点赋予一个语义标签,区分点属于哪种类别,从而将点云划分为不同的有意义区域。多见于复杂的室内或室外场景,通常伴有背景噪声,指标通常是mIoU, OA, and mAcc这三个
- 数据集:S3DIS(Stanford Large-Scale 3D Indoor Spaces Dataset)包含6个大型室内场景(大楼的6个区域)。 场景复杂且有噪声,适合验证语义分割的实际效果。
- 区域 5 测试:SSL 预训练模型在除最大区域 5 之外的所有区域上进行微调,被选为测试集。
- 六倍交叉验证:依次选择区域 1-6 作为测试集,并在剩余的 5 个区域进行微调。
![[Pasted image 20250705125146.png]](/upload/Pasted%20image%2020250705125146.png)
目标检测
- 找到物体的空间位置,用 6自由度(6 DoF) 的3D包围盒(bounding box)描述,即物体的位置(X, Y, Z)+ 旋转角度(绕X、Y、Z轴的旋转),并在复杂场景中区分其类别的任务
- 使用的评估指标是平均精度 (AP),它衡量 3D 边界框在不同召回级别的精度, AP@0.25:预测框与真实框 IoU ≥ 0.25 时算作正确,AP@0.5:IoU ≥ 0.5,要求更严格,只有更准确的预测才算正确
- 实验数据集:SUN RGB-D和ScanNet
![[Pasted image 20250705130748.png]](/upload/Pasted%20image%2020250705130748.png)
未来的方向
- 自监督学习不应被单独研究,而应与其他先进领域的方法相结合
- 讨论未来的研究方向,可以提升自监督表示的质量,对下游任务(如分类、检测、分割)的迁移性能
小样本学习和零样本学习
- SSL 研究有大量公开可用的标记数据集。然而,真实场景往往面临数据短缺或质量挑战,如损坏的标签、缺失的信息和不均匀的分类
- 小样本学习 (FSL) 被认为是一种潜在的解决方案,它允许网络在数据量非常少的情况下进行训练。
- 也可以在没有训练样本的测试任务中识别以前没有见过的新样本类型。这种方法通常被称为零样本学习 (ZSL)。SSL 和 FSL (ZSL) 都可以自由模型依赖于大型注释数据集并降低成本。此外,这两者的结合可能会提高模型的泛化能力。
多模态交互与融合
- 大多数研究仍只关注点云本身,很少考虑点云与其他模态之间的对齐与融合关系
- 近年有部分研究尝试打破单一模态的限制,开始设计用于多模态对齐和融合的模型,主要是点云 + 图像之间的融合
- 预计更多的研究集中在具有更多样化模式的跨模态SSL上,例如自然语言、雷达和语音,利用每个模态的独特特征以及它们之间的协同作用来构建交通系统,例如自动驾驶和交通场景分析,具有更人工智能
分层特征提取
- 为了应对一些复杂的下游任务,比如:目标分类(object classification) 部件分割(part segmentation) 这两个任务的目标有点“冲突”,一个偏全局,一个偏局部。因此,自监督学习的模型需要既能看到全局大图景,又能聚焦局部细节。
- 特别是,需要考虑层次结构中不同级别的特征表示之间的交互来发现隐式关系。因此,我们建议在 SSL 范式中嵌入分层特征提取,以提高模型从点云中捕获全局和局部特征的能力。
多任务预训练
- 很少有研究尝试在预训练阶段同时进行多个任务的训练。
- 多任务训练时,不同的预训练任务(pretext tasks)之间可能不兼容,比如一个任务希望模型关注全局信息,另一个希望模型专注局部结构,方向不同。
- 每个任务有自己的损失函数(loss),多任务就有多个 loss,要合理平衡这些 loss 的权重,才能让模型稳定地更新参数,不至于偏向某一个任务。
- 因为训练时只用了单一任务作为预训练目标,所以导致模型在某些下游任务表现很好,但在另一些就效果不佳。
- 不同的预训练任务(代理任务/proxies)可以从不同角度让模型理解点云数据。如果能把多个任务一起训练,模型就能学习到更全面、更丰富的表示
理论支撑不足与可解释性差
- 模型为什么有效、背后的机制是什么,很多时候并没有清晰的理论解释。
- 训练过程就像一个“黑箱子”,我们把数据和任务输入进去,输出了结果,但中间发生了什么并不清楚,这使得人类很难分析和信任模型的判断。
- 目前的技术论文大多采用消融实验来证明方法的有效性,即去掉某个组件或损失项,看性能有没有变化,往往是基于经验的
- 我们建议未来的研究应该包含更多对可解释理论的调查,例如互信息或因果推理的成熟理论,可以应用于网络结构和损失函数的设计。
总结
贡献
- 介绍了基础概念
- 本论文系统地综述了基于深度神经网络的点云自监督学习方法,
重点是近年来的代表性工作,涵盖了方法原理、设计思路与实验效果。 - 另外提出了一个新的体系
- 还给出了数据集,和方法性能的对比
- 给出未来的方向
评论区